AI Is Changing Research - AI Audits Will Change How We Run It
The growing need for transparency, documentation, and human oversight in AI-assisted research

AI audits are moving from "future governance" to everyday operational reality for research leaders, because the systems that shape research workflows (recruitment targeting, transcription, coding, summarisation, segmentation, synthetic respondents, and vendor platforms) are now routinely powered by machine learning and, increasingly, generative AI. Meanwhile, regulators and standards bodies are converging on a consistent expectation: if an AI system can influence people's rights, opportunities, access, or wellbeing, you need (a) documentation, (b) risk assessment, (c) testing and monitoring, and (d) accountable humans who can intervene. The EU AI Act makes this explicit by requiring a risk-management system for high-risk AI, along with data governance, technical documentation, logging, transparency for deployers, human oversight, and lifecycle accuracy/robustness/cybersecurity.
Several trends underline why research teams should prepare now rather than “when asked.” In 2024, 78% of organisations reported using AI, up from 55% the year prior (a step-change that expands audit scope across functions, including insights). Reported harms are rising the AI Incidents Database count has also reached 233 AI-related incidents in 2024, a 56.4% increase over 2023. Regulation is accelerating in the United States; the number of AI-related regulations tracked in the AI Index rose to 25 in 2023, up from 1 in 2016, with a 56.3% year-on-year increase. And in the UK, the assurance market is growing rapidly: the government's analysis identified 161 UK-based AI assurance firms, with 80% of specialised firms showing growth signals, suggesting that third-party auditing and assurance capacity is becoming an industry.
For UX Research and Market Research, "audit readiness" is not just a compliance posture. It is a quality posture. In practice, auditors want clear consent, dataset provenance, bias checks, reproducibility of analysis, secure handling of recordings/transcripts, vendor contracts with audit rights, and improvements in research credibility with stakeholders and in reducing the risk of reputational events triggered by misused participant data.
Why AI audits land in research functions
Research functions now sit on an “AI value chain” even when they do not build models. A research leader might commission an insight study that relies on a third-party platform for recruitment, translation, transcription, summarisation, qualitative coding, or panel fraud detection. Under modern governance approaches, that still counts as “using” or “deploying” AI: you own the decision to introduce automated processing into a workflow that touches personal data, sensitive attributes, or vulnerable populations.
In parallel, the "audit" concept is broadening. The UK government's Introduction to AI assurance frames assurance as a family of techniques used to evaluate whether an AI system is working as intended and meeting relevant requirements (regulation, standards, organisational values), not merely a financial-style audit. The UK's AI assurance roadmap also reflects a push toward an ecosystem in which independent assurance becomes the norm for procurement and deployment decisions, particularly for higher-risk use cases.
For researchers, this shift has two practical implications:
First, audits will increasingly examine research processes (how you recruit, consent, store/retain, analyse, and report) rather than only models. This is especially true where research uses vendors’ black-box models or general-purpose AI tools. The UK ICO’s AI and data protection guidance and its AI auditing framework focus strongly on data protection principles, i.e., process and governance, not just technical metrics.
Second, the boundary between “research” and “product decision-making” is blurring. For example, synthetic respondents can rapidly simulate reactions to concepts, but they also risk contaminating decision pipelines with artefacts of model training data rather than lived customer reality. Industry guidance has begun to treat synthetic participants as a major methodological and ethical frontier for market research. Academic work similarly cautions that “silicon samples” can vary materially from human samples, with results depending on prompts, model choice, and evaluation design.
A useful way to make sense of AI audit frameworks is to treat them as answering three audit questions:
What is the required standard? (law/standard/principle),
What counts as evidence? (documentation, logs, tests),
And who is accountable? (provider vs deployer vs third parties).
Audit scope and controls for UX Research and Market Research
A practical way to tailor AI audit readiness to research is to define a “research AI system” broadly: any model, automated decision rule, or generative tool that materially influences recruiting, data collection, analysis, synthesis, or reporting. Under this definition, your audit scope includes not only bespoke models but also vendor tools, plug-ins, browser-based LLMs, and “AI features” embedded in research platforms.
Below are the most audit-relevant risk clusters for research, with controls that map cleanly to EU AI Act high-risk requirements, NIST AI RMF functions, UK ICO guidance, and common industry documentation practices.
Data collection, consent, and lawful basis risks are central because research regularly collects personal data and, depending on the sector, often sensitive data (health, biometrics, political views, etc.). The EU AI Act's high-risk data governance requirements explicitly require documenting data origin and collection purpose, and they emphasise bias assessment and mitigation in datasets. UK ICO guidance similarly frames AI compliance through data protection principles, which directly touch research recruitment scripts, consent flows, purpose limitation, minimisation, retention, and transparency obligations.
Bias and representativeness risks arise because AI can change who is recruited (via lookalike targeting, fraud detection, or eligibility screening), how responses are interpreted (via sentiment analysis and topic modelling), and which narratives "win" in synthesis. The EU AI Act's dataset provisions include explicit examination and mitigation of biases that could lead to discrimination and harm fundamental rights. NIST similarly foregrounds mapping impacts to individuals and communities, and stresses that risk mapping and measurement should include third-party components.
Explainability and interpretability risks arise in research in two ways: first, when AI outputs drive decisions about product direction or customer policy; second, when AI is used to justify findings ("the model says users feel X"). EU AI Act transparency duties require systems to be sufficiently transparent so that deployers can interpret their outputs and use them appropriately, supported by instructions for use. In the tooling ecosystem, explainability frameworks exist precisely because "one explanation does not fit all," reinforcing the idea that explainability is a design choice that must be tailored to stakeholder needs and model context.
Reproducibility and audit trail risks are especially acute with generative AI. Qual coding or thematic synthesis supported by LLMs can be fast, but it is also sensitive to model versioning, sampling stochasticity, prompt drift, and hidden vendor updates. This is why both regulatory frameworks and good practice emphasise logging and documentation: the EU AI Act requires logging capabilities for high-risk systems to support traceability and post-market monitoring. For research workflows, analogous logging of prompts, model version, parameters, input corpus hash, and human edits is the only way to make AI-assisted analysis auditable.
Privacy, confidentiality, and participant safety risks extend beyond compliance: they affect willingness to participate and can cause harm if sensitive materials are leaked to vendors or inadvertently re-identified. Synthetic data is often proposed as a mitigation, but research shows that it can still pose privacy risks and requires quantification rather than assumptions. Meanwhile, LLM hallucination is a known phenomenon with a large body of research on definitions, detection, and mitigation; in a research context, hallucinations can become “false evidence” if AI-generated summaries are not verified against source transcripts.
Vendor and third-party model risks are not optional to address, because most research teams rely on third-party tools. NIST explicitly notes that risks related to third-party software, hardware, and data can complicate risk measurement and calls for policies/procedures addressing third-party AI risks across the supply chain. EU AI Act definitions also recognise downstream providers that integrate models from another entity, reinforcing the need to manage "model in the middle" accountability.
Synthetic respondents and "simulated people" present a special audit frontier for MR. Industry discussion notes a rapidly growing interest in synthetic respondents, while acknowledging fundamental questions about how LLMs relate to the world and how synthetic respondents relate to real-world equivalents. Peer-reviewed work on silicon sampling compares silicon and human samples and finds that results vary considerably across studies, highlighting that, without rigorous validation, synthetic respondents can introduce methodological risk.
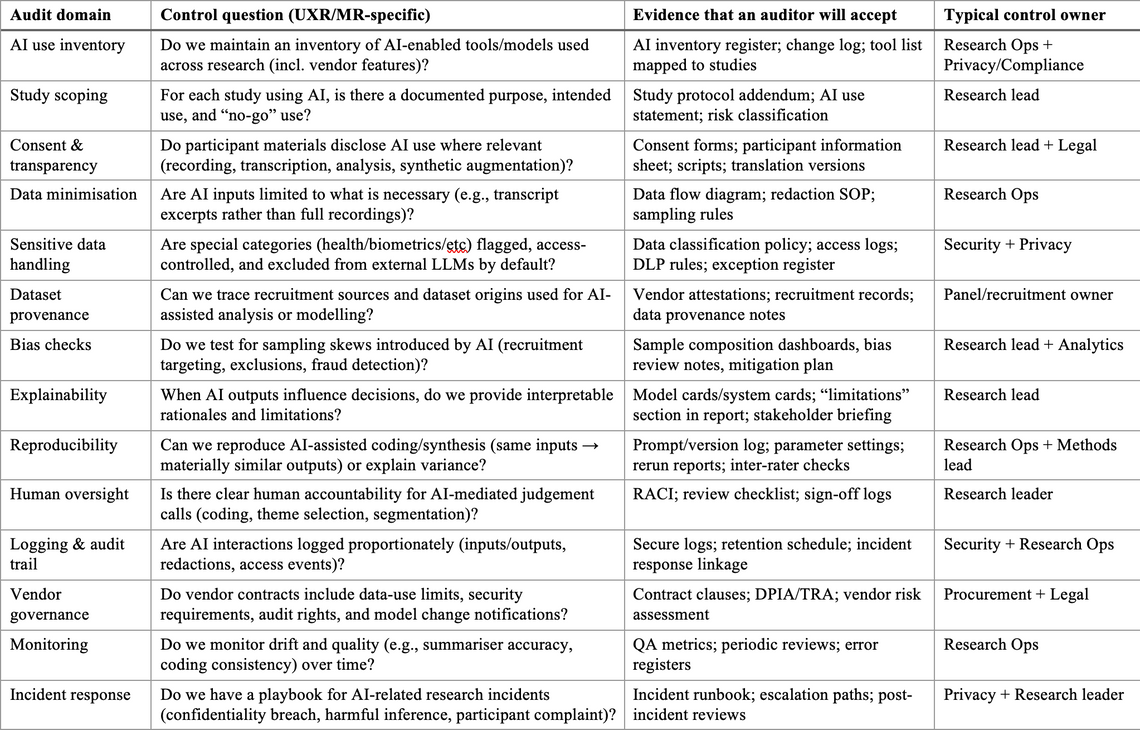
Sample AI audit checklist table tailored to UXR/MR
Practical preparation steps for research teams and leaders
The most effective audit preparation for UXR/MR is to treat audit readiness as a research operations capability rather than a one-off compliance project. The steps below are sequenced to produce tangible artefacts quickly while building toward mature governance.
Start with governance and role clarity. NIST's GOVERN function explicitly calls for mechanisms to inventory AI systems and for clear roles and responsibilities to manage AI risks; it also emphasises policies/procedures for risks arising from third-party software/data. Your research function, therefore, needs a lightweight governance layer: a named accountable owner for "AI in research," a decision forum for higher-risk AI uses, and a clear escalation path to privacy/security/legal. Where your organisation is aligning to ISO/IEC 42001, this governance layer fits naturally into a management-system approach with defined responsibilities and continuous improvement cycles.
Build an "AI-in-research inventory" before you are asked for it. This inventory is the cornerstone evidence for almost every framework: it allows scoping, risk classification, and targeted controls rather than blanket bans. NIST highlights inventories directly and notes that procurement functions are themselves AI actors when acquiring third-party models and services. Your inventory should include tool name, vendor, feature used, data types processed, whether data leaves your environment, retention settings, model versioning behaviour, and whether humans rely on outputs for decisions.
Add an "AI annex" to your standard research documentation. Auditors rarely want one giant report; they want consistent evidence across projects. The EU AI Act requires technical documentation for high-risk systems and emphasises transparency and instructions for use. At the same time, your research work is not always "high-risk AI," the documentation habit is transferable. A research AI annex can standardise on intended use, limitations, data minimisation choices, bias checks performed, and the reproducibility/logging approach.
Implement impact assessments proportionate to risk. The language differs across jurisdictions: data protection impact assessments, algorithmic impact assessments, and socio-technical assessments, but the shared goal is to anticipate and mitigate harms. The UK ICO guidance on AI and data protection is designed to help organisations apply UK GDPR principles to AI, which in practice means formalising risk assessments for AI-driven processing of personal data. NIST also notes that AI system impact assessment approaches can help actors understand harms in specific contexts. For research teams, a pragmatic approach is a two-tier assessment: a short screen for most studies and a deeper review for studies involving sensitive data, vulnerable populations, biometric inference, or automated eligibility decisions.
Operationalise testing, QA, and monitoring as research quality controls. The EU AI Act's high-risk requirements explicitly require systems to be tested against defined metrics and thresholds and to perform consistently throughout their lifecycle, supported by logging and monitoring. For research, translate this into: (a) sampling QA (are recruitment filters excluding groups?), (b) analysis QA (does AI coding align with human coding beyond surface agreement?), and (c) drift monitoring (does a vendor update suddenly change summaries or sentiment outputs?). When using LLMs for synthesis, integrate "grounding checks" to prevent hallucination, as it is well-documented and can contaminate research narratives if not caught.
Train for AI literacy in a research-specific way. EU AI Act requires organisations to take measures to ensure a sufficient level of AI literacy for staff operating or using AI, accounting for context and the people on whom systems are used. For research teams, literacy should focus on what data is exposed when using tools, what “model updates” mean for reproducibility, how to interpret model confidence/uncertainty (and when not to), and how to communicate limitations transparently to stakeholders.
Harden procurement and vendor management clauses. NIST explicitly highlights risks from third-party software/data and stresses the need for policies and controls. Procurements for research platforms and AI tools should embed: data-use and retention restrictions (including "no training on our data" where relevant), breach notification timelines, model-change notification, transparency artefacts (system cards/model cards), audit rights, subcontractor disclosure, and the ability to export logs needed for audits. For research platforms handling recordings and transcripts, there is a need for clarity on where processing occurs and what is stored, in line with UK ICO expectations for transparency and lawful processing.
Treat synthetic respondents as a controlled method, not a shortcut. Industry work describes both the opportunity and the unresolved question of how synthetic respondents relate to real-world equivalents. Academic findings reinforce that outputs can vary considerably and that evaluation must go beyond superficial fit. Practically, this implies a control stance: synthetic respondents may be permissible for early ideation, sensitivity analysis, or hypothesis generation, but require explicit labelling, validation against human data before decisions, and clear statements that synthetic outputs are not evidence of customer truth.
Templates, checklists, and an audit-readiness timeline
The fastest way to become audit-ready is to standardise artefacts. Auditors trust what they can inspect, compare, and trace across time. The templates below are designed to be lightweight enough for research teams but structured enough to satisfy common audit expectations from NIST, EU AI Act controls (where relevant), and UK ICO-style assessments.
A research AI system registration template should include the system/tool name, owner, vendor, purpose, data types, sensitive data flags, processing location, retention, model/version behaviour, user access model, and whether the tool is used for decision-making versus support. This aligns with NIST's call for AI inventories and for resourcing governance.
A study-level AI use statement template should capture why AI is used, which tasks are automated, what remains in human judgement, limitations, and any participant-facing disclosures. The value is not only compliance; it is research integrity and stakeholder trust, echoing the EU AI Act's emphasis on transparency, enabling deployers to interpret outputs appropriately.
Documentation artefacts for models and datasets provide consistent “audit language.” Model Cards (originally proposed as short documents accompanying models) and Datasheets for Datasets (proposed as standardised dataset documentation) can be adapted into research operations without becoming heavyweight MLOps. The TensorFlow Model Card Toolkit exists to make model-card creation systematic, and Data Cards playbooks support similar dataset-style documentation.
A synthetic respondent evaluation template should include intended decision use (if any), prompt protocol, demographic conditioning method, validation approach (against known human data), and explicit limitations. This is consistent with research-industry guidance highlighting both opportunities and unresolved validity concerns.
Conclusion
To make audits practical, I recommend committing to a standard, reusable evidence pack for any research AI use case above “low” risk. The evidence pack should include: an up-to-date inventory entry; a one-page research AI annex; a data flow and retention diagram; participant-facing disclosures/consent language; QA evidence of bias and representativeness; reproducibility logs for AI-assisted analysis; and vendor documentation (contracts, security statements, model/system cards, where available).
I am a research strategist who partners with businesses, technology organisations, and SaaS teams to turn research into clear strategic direction and measurable impact. I work hands-on across the full research lifecycle, spanning academic, consulting, industry, and policy research, with a strong focus on evidence-based decision-making.
My expertise brings together data-driven insights, UX and CX (Voice of Customer) research, strategic research planning, stakeholder engagement, and robust survey and measurement design. Using a mix of primary and secondary research methods, I help organisations move beyond surface-level insights to understand what truly drives customer behaviour, product adoption, and long-term value.
As a customer-centred, insights-led researcher, I focus on uncovering human behaviours, habits, motivations, and attitudes to help teams design products, services, and strategies grounded in real-world needs. I’m particularly drawn to emerging technologies and SaaS environments, where strong research can shape how people learn, work, and interact at scale.
Beyond UX and customer research, I bring deep experience in strategic research program design, vendor management, and cross-sector collaboration. I work closely with senior stakeholders and interdisciplinary teams to ensure research findings are translated into actionable strategy, product roadmaps, and policy-ready recommendations.
I actively contribute to the research and technology community through thought leadership, including writing on Medium and publishing a LinkedIn newsletter focused on research practice and emerging industry trends. I also partner with SaaS companies to evaluate user research platforms and capabilities, providing practical, real-world feedback that informs product innovation.
Forward-thinking and outcomes-focused, I bridge academic rigour, industry innovation, and strategic insight to help organisations build better products, make confident decisions, and deliver meaningful customer experiences.