Invisible Bias in AI‑Assisted Market Research: AI Didn’t Create Bias, It Just Made It Harder to Ignore
What does “invisible bias” mean in AI‑assisted market research

“Invisible bias” is the kind of systematic skew that doesn’t announce itself as bias because it is embedded in data pipelines, model behaviour, and the way humans interpret outputs. It can sit quietly inside a dashboard metric, a clustering solution, a summary of open‑ends, or an “insight narrative” that looks polished and plausible but subtly sidelines certain groups, contexts, or meanings.
A helpful starting point is the standards-aligned definition of bias in AI: a systematic difference in the treatment of objects, people, or groups compared with others. From a technical perspective, some bias is necessary for learning patterns, but it becomes unwanted bias when it leads to unjustified differential treatment and unfairness.
In AI-assisted market research, invisible bias typically manifests across three interacting layers:
Bias in data (what we observe, collect, and label)
Bias in algorithms/models (how patterns are learned, represented, optimised, and generated)
Bias in interpretation and decision-making (how humans trust, rationalise, and act on AI outputs)
This aligns with standards guidance that treats bias as a lifecycle issue spanning data collection, training, testing, evaluation, and use.
The Australian "The Research Society" explicitly positions AI as increasingly "embedded in many aspects of research work" across data collection, analysis, reporting and communication, and flags risks in sampling, sentiment and emotion analysis, summarisation, and synthetic data, including a dedicated section on “Bias and Fairness in AI models.”
This matters because invisible bias is rarely a single defect; it is more often an end-to-end property of the system you built (and the organisational habits around it).
A practical taxonomy for market research teams
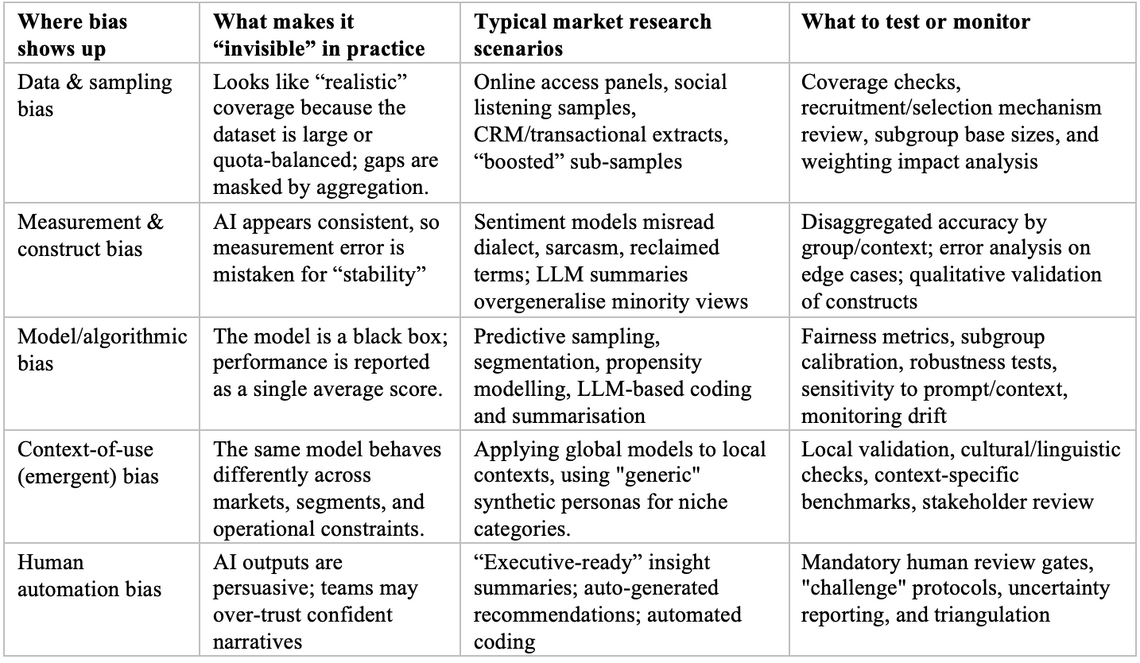 Bias becomes invisible when it is normalised by the process, especially when automation makes the process faster than reflection can keep pace.
Bias becomes invisible when it is normalised by the process, especially when automation makes the process faster than reflection can keep pace.
Bias before AI: the uncomfortable history of “traditional” market research
It is tempting to treat AI as the moment bias entered market research. Methodologically, that’s not true.
Traditional market research entails well-documented risks of bias in sampling, measurement, and inference, and many of these risks were managed rather than eliminated through professional standards, quality assurance, and researcher judgment. Two examples illustrate why bias existed long before AI:
Quota sampling is beneficial but not equivalent to random selection. In an ESOMAR paper on synthetic data, the authors note that quota sampling is designed to replicate demographic structure, but that the resulting samples are "biased" by the quota method and "by definition" not randomly selected; they emphasise that quota sampling must be used with caution to avoid selection bias. This isn't a critique of quota sampling; it’s a reminder that the statistical guarantees people intuitively associate with "representative" may not hold as they assume they do.
Opt‑in online panels are convenient and systematically different. A 2025 open-access study in Survey Methods: Insights from the Field finds that panellists exhibit distinct online behaviours (more active and informed online participation, more posting, more political expression) and concludes that the population of online panellists "cannot represent the general population," explaining why generalisations from access panels are likely to be biased.
Add to these classic issues: response biases, framing effects, social desirability, interviewer effects, and “what we asked is not what people meant.” AI did not invent these; it inherits them.
What AI changes is the speed, scale, and opacity of decision-making:
We operationalise constructs (e.g., “brand love,” “trust,” “intent”) through models rather than solely through instrument design.
We apply automation to sampling (predictive recruitment), coding (topic- and sentiment-based automation), and reporting (summaries and slide-narrative generation).
We increasingly integrate new data streams (social, behavioural, transactional) in which the sampling frame is ambiguous and platform data collection can be biased at multiple stages.
This shift creates the conditions for invisible bias: more moving parts, fewer people who understand the whole chain, and greater confidence in machine outputs.
Why AI doesn’t create bias but makes it louder and harder to ignore
The claim “AI didn’t create bias” is not a defence of AI. It’s a diagnosis of where the bias comes from and why it becomes harder to dismiss once AI is in the workflow.
Bias is often pre-existing; AI makes it scalable.
A foundational observation from early scholarship on bias in computer systems is that bias can become pervasive when a system is complex, widely disseminated, and not transparent to users; complexity can keep bias “hidden in the code,” and users often have no mechanism to appeal or interrogate the system’s influence.
AI systems amplify that pattern because they learn statistical regularities from historical or observational data (including inequities and omissions).
Optimise for predictive accuracy or engagement, which can reward proxies for protected characteristics.
Produce outputs that appear internally coherent even when they are built on skewed inputs.
Information Commissioner's Office, UK data protection authority, distinguishes bias (a trait of decision-making, human or institutional) from discrimination (adverse effects resulting from bias), and notes that because AI systems learn from data that may be unbalanced and/or reflect discrimination, they may produce outputs with discriminatory effects.
In other words, AI is often a mirror with an amplifier attached. The mirror reflects historical and representational distortions; the amplifier applies them consistently at scale.
AI also introduces “technical” and “context-of-use” bias
Saying AI doesn’t create bias is not the same as saying AI can’t introduce new bias mechanisms. It can:
Technical bias: choices in training data, labels, features, loss functions, and thresholds can systematically disadvantage certain groups, even when no one intends harm. Standards guidance treats bias as something to measure and treat across the full AI lifecycle.
Emergent bias: the same model used in a new context can produce skewed results because meaning, language, and behaviour change across cultures, markets, and time. For example, practitioner guidance warns that applying consumer data from one region to predict outcomes in another without contextual adaptation can lead to errors.
The “persuasion problem”: automation bias makes bias cognitively invisible
Here is the part of market research that market research leaders most often underestimate: bias is not only in the model; it is also in the relationship between the model and the analyst.
The Research Society cautions that AI is "implicitly persuasive" in how it presents insights, and that researchers must disclose limitations and potential sources of bias, especially when AI can answer "generically" from its training set rather than from project data.
Decades of human-computer interaction research support this concern. A classic experimental study on decision aids found that participants using an imperfectly reliable automated aid made errors of omission (missing events not flagged by the aid) and errors of commission (following the aid even when it contradicted valid indicators).
In market research terms: if the AI-coded theme doesn’t appear, teams may stop looking; if the AI summary sounds confident, teams may stop challenging.
How bias propagates in AI-assisted market research
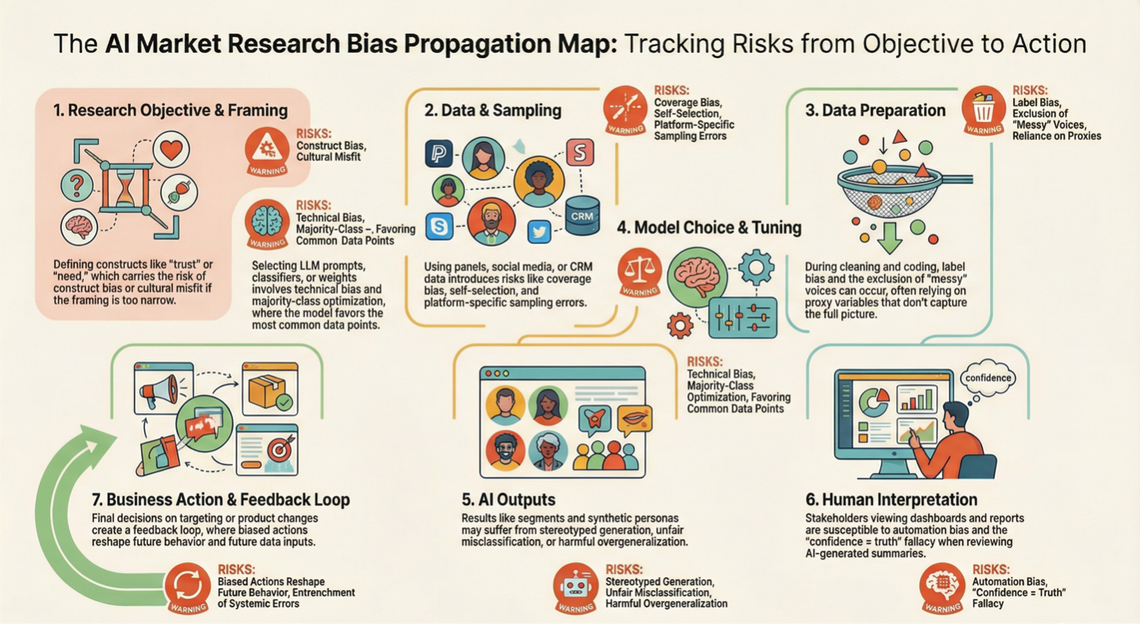
Standards guidance explicitly places bias management across lifecycle phases (from data collection through use), reinforcing that this propagation is not hypothetical; it is the default unless interrupted by design.
Evidence and case studies: what invisible bias looks like in real AI‑assisted insight work
This section mixes academic evidence (what we can measure) and industry evidence (what is being productised). Invisible bias sits at their intersection.
Synthetic respondents and synthetic data: “convincing” is not the same as “true”
Industry is rapidly experimenting with synthetic respondents (AI personas that mimic human responses). NielsenIQ defines synthetic respondents as artificial personas generated by ML models to mimic responses, useful for quickly evaluating concepts. It warns that market research vendors rushing to deliver solutions can produce outputs that pass a "gut check" while lacking the appropriate tools or data for accuracy, highlighting the “convincing but unsubstantiated” problem.
The invisible bias risk is structural: Synthetic outputs can smooth away variance, predominantly minority viewpoints, because many generative methods reproduce dominant patterns. - Synthetic tools can recycle past distributions, embedding yesterday’s representation into tomorrow’s strategy.
The International Chamber of Commerce and ESOMAR-aligned Congress paper frames synthetic samples as potentially helpful for boosting underrepresented samples, but stresses responsible deployment, mapping limitations and use cases, and proposes a validation framework explicitly, since synthetic generation is only as reliable as the original data and validation discipline.
A major practical twist is fraud: Ipsos warns that generative AI can be used to generate fraudulent responses and argues that if validation focuses solely on accuracy while ignoring transparency and ethics, it fails the “Truth, Transparency and Trust” test.
The invisible bias here is twofold: a biased synthetic representation and biased confidence (“it looks clean, so it must be right”).
LLMs simulating public opinion: performance gaps become representativeness gaps
A 2024 peer-reviewed study in Humanities and Social Sciences Communications evaluates ChatGPT-based public opinion simulation using socio-demographic prompts drawn from the "World Values Survey". It reports performance disparities across countries and demographic groups, with biases related to gender, ethnicity, age, education and social class. It argues for improving representativeness before integrating LLMs into public opinion research.
For market research, the key takeaway isn’t “LLMs are biased” (we already know that). The deeper point is:
If an AI model performs better for some populations than others, then the model is effectively acting like a differential response-rate mechanism, a new kind of representativeness problem.
That is an invisible bias as a methodological error: the model becomes a non-random filter on human opinion.
LLMs as virtual survey respondents: prompt design as a bias dial
A 2025 arXiv study introduces evaluation settings and a benchmark suite for LLM-based socio-demographic survey simulation, testing mainstream models and showing that context and prompt design materially impact simulation fidelity and can expose failure modes.
This is directly relevant to market research teams building “synthetic target respondents” or using LLMs to fill missing attributes. Prompting choices become methodological choices and, therefore, ethical choices because they decide which demographic cues are “salient” to the model and what stereotypes or correlations it may activate.
Opinion summarisation: minority viewpoints can disappear in a single “theme”
Market research relies on summarisation: turning hundreds of verbatim statements into a narrative. If that narrative is AI-generated, invisible bias often shows up as representation loss, a technically clean summary that disproportionately reflects high-frequency viewpoints.
A 2025 paper on opinion summarisation proposes "frequency framed prompting" (REFER), and reports improved fairness in LLM opinion summarisation, motivated by the idea that referring to explicit classes can reduce systematic bias in statistical reasoning and, by extension, in summaries.
How you ask the model to summarise can change which voices survive compression.
Social listening and sentiment analysis: dialect and identity as hidden confounders
Sentiment and toxicity tools are standard in brand tracking and category intelligence. Bias here becomes invisible because outputs are numeric, scalable, and apparently objective.
A 2024 arXiv paper reports systematic biases in toxicity and sentiment methods toward utterances that use African American English (AAE) expressions, with consistent results indicating that greater use of AAE expressions can lead speakers to be perceived as substantially more toxic, even when discussing nearly the same subject matter.
A 2025 open-access paper on LLMs for sentiment analysis quantifies social bias across prompts varying in gender, politics, age, and ethnicity and finds that social bias persists; fine-tuning can improve fairness but does not always eliminate bias (notably for age groups).
For market research, this has immediate consequences. If sentiment is a KPI in a tracker, biased sentiment is not just an analytic error; it is a systematic measurement bias that can tilt brand strategy away from communities whose language is misread.
An Australian industry signal: bias is a capability challenge, not a “fix it later” issue
A 2023 open-access study in Industrial Marketing Management proposes an “algorithmic bias management capability” framework for AI-driven marketing analytics, based on research in the Australian financial services industry. It highlights data bias as an antecedent of model and deployment bias and posits that model and deployment bias mediate the relationship between data bias and customer equity outcomes. This is important because it reframes bias management as an organisational capability, something you build systematically rather than a one-off “model cleanup” task.
Ethical, social, and business implications of invisible bias
Invisible bias is not merely a technical defect. In research organisations, it becomes a compound risk across people, governance, and market outcomes.
Ethical and social implications
Unjust differential impact: When AI learns from unbalanced or discriminatory data, its outputs can have discriminatory effects, even without intent. Regulators explicitly treat this as a fairness problem, not just an optimisation trade-off.
Misrepresentation and stereotyping: Professional guidance in Australia flags that automated analysis may misinterpret open‑ended responses, reinforce stereotypes, or overreach in profiling, especially for minority audiences.
Loss of agency and informed consent: If participants are unaware that they are interacting with AI, or if AI is used in ways not disclosed, trust and ethical legitimacy erode. The Research Society guidance explicitly calls for disclosure and opt‑out/escalation mechanisms in AI-human interactions.
Business implications
The business costs are often more immediate than ethics teams assume:
Strategic misallocation: If synthetic respondents or LLM simulations are treated as substitutes for people, investment may follow "clean" yet inaccurate insights. NielsenIQ warns that convincing answers differ from accurate ones, mainly when business decisions rely on data integrity.
Local market failure: Practitioner guidance emphasises that training on data from one region and applying it to another without contextual adaptation can lead to errors. This issue becomes more severe as global tools scale.
Reputational and compliance exposure: Bias-related harms increasingly intersect with expectations regarding privacy, transparency, and consumer protection, raising the risk of “silent failure.”
Privacy and data stewardship implications
Bias management often forces uncomfortable trade-offs: you may need demographic attributes to detect disparity, but collecting and using those attributes triggers privacy obligations.
The Office of the Australian Information Commissioner (OAIC) emphasises "privacy by design" in the development or refinement of generative AI models and notes that privacy obligations apply when personal information is used to train, test, or operate AI systems.
The OAIC also emphasises that de-identification is contextual: effective de-identification requires assessing re-identification risk with reference to both the data and the release environment. This matters because richer data linkages can reduce certain biases (e.g., by providing more context and improving subgroup evaluation) while increasing re-identification risk and governance burden.
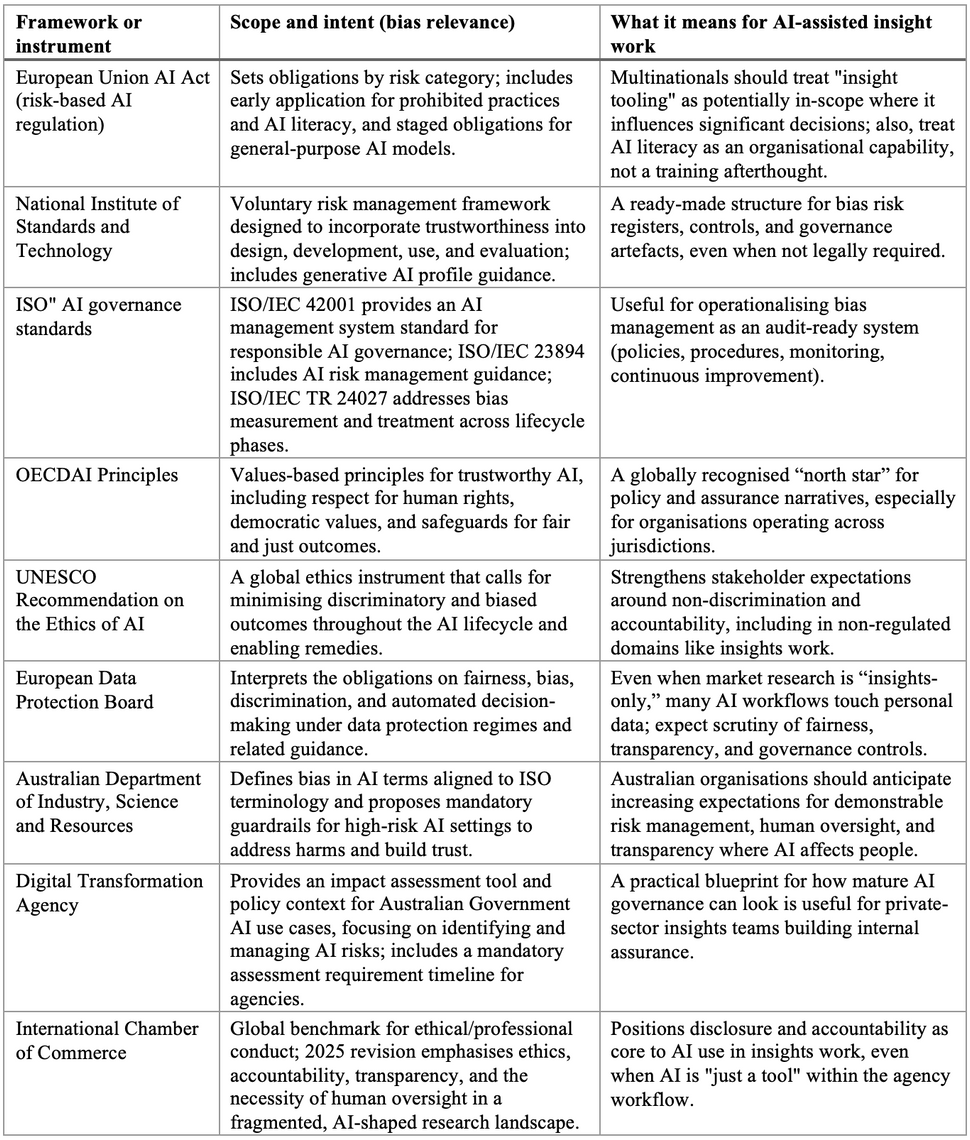
Regulatory guidance, standards, and ethical frameworks shaping expectations
A patchwork of AI regulations, privacy laws, professional codes, and technical standards increasingly governs the handling of bias in AI market research. The practical question for insights leaders is: what do these frameworks require of you?
A comparative view of the most relevant frameworks
Practical strategies to identify, mitigate, and manage invisible bias
Invisible bias is best handled the way market researchers already handle many forms of methodological risk: define it, test for it, document it, and treat it as a continuous control process, not a one-time “model check.”
A mitigation map across the AI-assisted research lifecycle
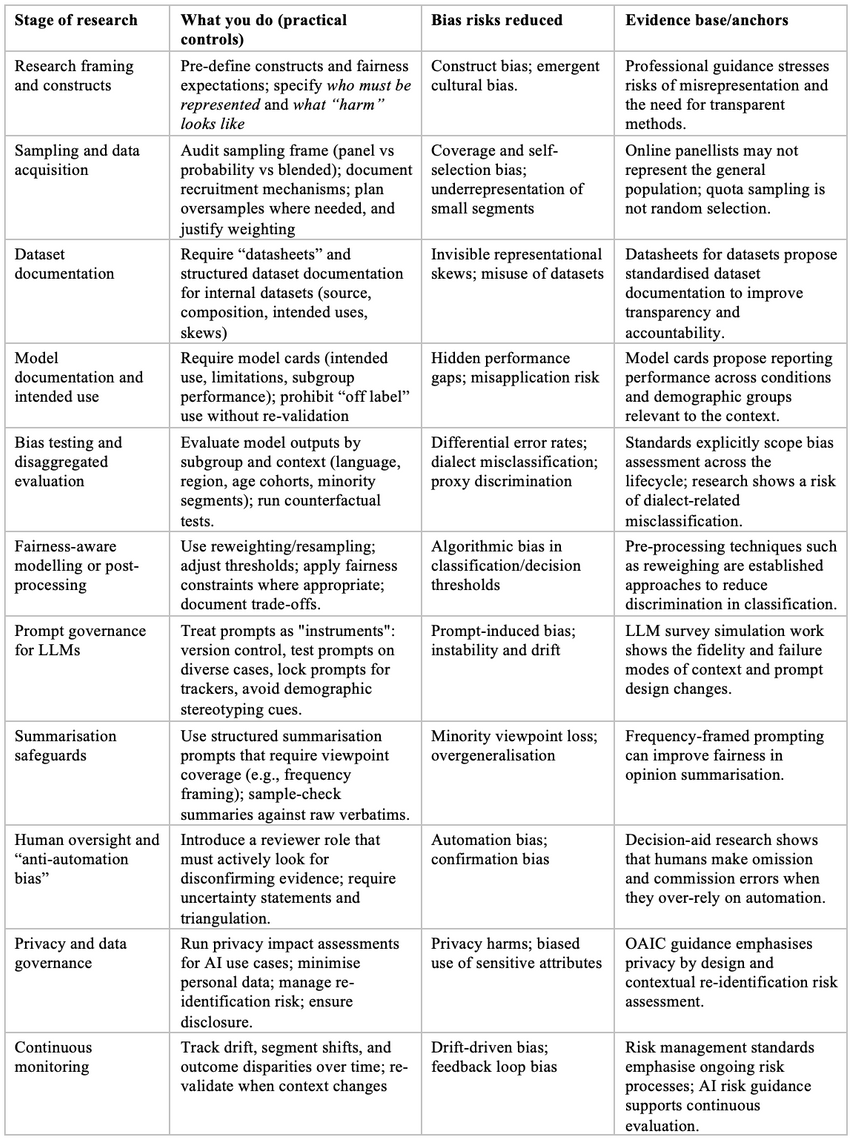
A bias “triangulation” discipline for insights teams
No AI-derived insight should “graduate” to recommendation status without triangulation across at least two different evidence types. For example: - If sentiment shifts, confirm with a sample of verbatims and (where possible) an independent measure (survey item, behavioural proxy, or qual).
If a synthetic respondent result looks "too clean," validate against a small but real sample before investing further.
If a segmentation model yields a surprising "new" cohort, test stability under reweighting and alternative modelling choices, and stress-test the segment narrative for stereotyping.
A governance move that changes outcomes: treat AI as a method, not a tool
The Research Society's guidelines explicitly state that AI use should be disclosed and that limitations and potential sources of bias should be communicated; they also warn that AI can hallucinate or generate generic content disconnected from project data.
The strategic shift is to operationalise this as follows: AI is part of your methodology (e.g., sampling, questionnaire design, or coding). Methodology is auditable; so, should AI. That is why standards such as ISO/IEC TR 24027 (bias measurement across the lifecycle) and ISO/IEC 42001 (AI management system governance) are helpful even for insight functions: they translate "be responsible" into repeatable organisational practice.
Future outlook: emerging technologies, research directions, and evolving standards
Three trends will likely define the next phase of invisible bias in market research.
1. Synthetic research will grow faster than synthetic governance
The market is already moving. Industry content positions synthetic respondents as supplements for early-stage ideation and concept triage but also highlights the need for continuous calibration, validation, and cautious trust.
The next risk is institutionalisation: once synthetic insights become embedded in innovation pipelines, confirmation loops can form (teams validate ideas against a synthetic mirror trained on past market structure). Practitioner frameworks that prioritise transparency and trust attempt to counteract this, but governance maturity will be uneven.
2. Agentic and end-to-end automation will concentrate bias risk.
As AI tools move from "assist with a step" to "run the workflow," bias propagation becomes faster and less observable. Research already shows that data-collection choices and model sensitivity can shape results, especially in social-media-derived insight pipelines, where bias can enter from the collection method to the modelling approach. The more steps delegated to AI, the more essential it is to establish explicit checkpoints that ensure visibility.
3. Standards and regulations will increasingly require proof, not promises
Two regulatory signals are particularly relevant for global organisations:
The EU AI Act timeline indicates a staged application, with prohibited practices and AI literacy obligations applying before the whole regime.
Australia is actively consulting on guardrails for high-risk AI and building practical assessment tools and policy requirements in government that normalise impact assessment and accountable ownership.
Meanwhile, research quality standards are evolving in parallel: ISO is preparing an update to ISO 20252 via a draft standard, underscoring that “how research is planned, carried out, and reported” remains a moving target as AI becomes embedded.
The “visibility paradox” to watch
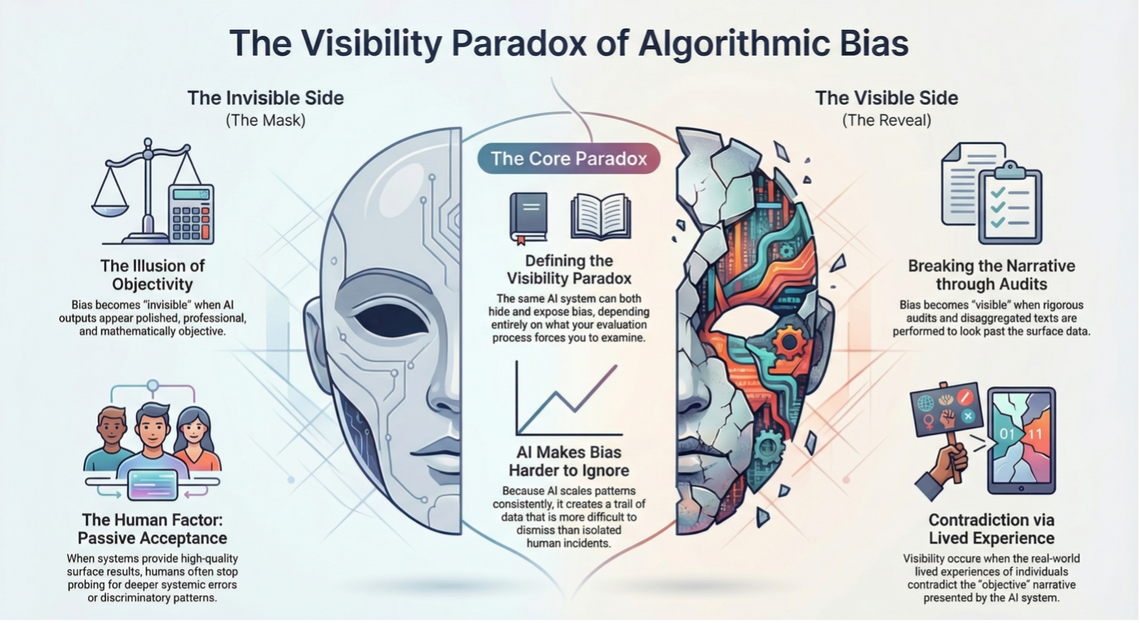 The leadership implication is straightforward: your governance determines whether AI reveals bias or conceals it. Professional guidance in Australia explicitly frames AI as persuasive and encourages disclosure and methodological clarity, the cultural counterpart to technical audit controls.
The leadership implication is straightforward: your governance determines whether AI reveals bias or conceals it. Professional guidance in Australia explicitly frames AI as persuasive and encourages disclosure and methodological clarity, the cultural counterpart to technical audit controls.
I am a research strategist who partners with businesses, technology organisations, and SaaS teams to turn research into clear strategic direction and measurable impact. I work hands-on across the full research lifecycle, spanning academic, consulting, industry, and policy research, with a strong focus on evidence-based decision-making.
My expertise brings together data-driven insights, UX and CX (Voice of Customer) research, strategic research planning, stakeholder engagement, and robust survey and measurement design. Using a mix of primary and secondary research methods, I help organisations move beyond surface-level insights to understand what truly drives customer behaviour, product adoption, and long-term value.
As a customer-centred, insights-led researcher, I focus on uncovering human behaviours, habits, motivations, and attitudes to help teams design products, services, and strategies grounded in real-world needs. I’m particularly drawn to emerging technologies and SaaS environments, where strong research can shape how people learn, work, and interact at scale.
Beyond UX and customer research, I bring deep experience in strategic research program design, vendor management, and cross-sector collaboration. I work closely with senior stakeholders and interdisciplinary teams to ensure research findings are translated into actionable strategy, product roadmaps, and policy-ready recommendations.
I actively contribute to the research and technology community through thought leadership, including writing on Medium and publishing a LinkedIn newsletter focused on research practice and emerging industry trends. I also partner with SaaS companies to evaluate user research platforms and capabilities, providing practical, real-world feedback that informs product innovation.
Forward-thinking and outcomes-focused, I bridge academic rigour, industry innovation, and strategic insight to help organisations build better products, make confident decisions, and deliver meaningful customer experiences.


