In the Age of AI, Every Insight Needs a Chain of Custody
An insight without a chain of custody is not an asset; it is an allegation

There is a sentence I keep returning to whenever a team proudly shows me a polished, AI-generated analysis: an insight without a chain of custody is not an asset; it is an allegation. It sounds severe until you sit with it for a moment. AI has made it remarkably easy to produce analysis, summaries, forecasts, recommendations, and persuasive narratives at a pace none of us could have managed a few years ago.
What it has not done is make any of those outputs inherently trustworthy. The speed of generation and the confidence we can responsibly have at the point of action are two very different things, and the distance between them has quietly become one of the most important strategic problems leaders now face.
Consider where most organisations sit. McKinsey reports that 88% of respondents say their organisations regularly use AI in at least one business function, yet only about a third say they have begun to scale it across the enterprise, and only 39% report any EBIT impact. The same research finds that AI high performers are notably more likely to have defined processes for when model outputs require human validation. In parallel, the University of Melbourne and KPMG found that 66% of people now use AI regularly while only 46% are willing to trust it. Inside workplaces, the picture sharpens further. 58% of employees intentionally use AI, 66% rely on its output without evaluating accuracy, 56% say they have made mistakes because of it, and 57% admit to presenting AI-generated work as their own. The gap between how much we generate and how much we trust is no longer a philosophical curiosity. It is a constraint on value.
That gap is why provenance, lineage, and validation now matter commercially and not only ethically. The organisations that learn to trace, document, test, and defend their insights will not just be safer. They will be faster at putting AI where it genuinely counts, because they will know which conclusions deserve trust.
What chain of custody actually means for an insight
The vocabulary matters here, because teams use three words loosely when they should keep them distinct. Provenance, as the W3C defines it, is information about the entities, activities, and people involved in producing something, enabling others to assess its quality, reliability, and trustworthiness. It answers the questions: what is this thing, who produced it, and why should I trust it? Lineage, the discipline behind modern data-lineage systems, answers a different question: where did the data or artefact travel, and what transformations happened along the way. Chain of custody, in the evidentiary sense NIST uses, answers a third: who handled it, when, under what authority, and for what purpose. For an AI-generated insight, leaders need all three working together rather than any one in isolation.
When you adapt these ideas to decision-making, an insight chain of custody becomes the traceable record of the evidence, transformations, models, prompts, human interventions, approvals, and tests that produced an analytic conclusion. An insight has a complete chain of custody when a reviewer can reconstruct its sources, every material transformation, every AI or human intervention, and every validation step that led to the final claim. In practice, that points toward what I think of as an insight manifest, a short record that travels with the conclusion. It captures the source datasets and documents used, the retrieval and selection logic, the model and version, the prompts or prompt classes, any material parameters, the intermediate summarisation steps, the human edits and approvals, and the tests used to verify factuality, relevance, bias, privacy, and decision fitness. It is the text-and-analytics equivalent of the Content Credentials now appearing in media, which record how a piece of content was created and edited across its lifecycle.
It helps just as much to be clear about what chain of custody is not. It is not the same as explainability on its own, because a model can be explainable in principle while leaving no audit trail of how a specific output was produced. It is not merely a compliance register, because a register can list systems without preserving the transformation history of any individual output. And it is not just a logging problem, because logs without governance, retention, validation, and human accountability become exhaust rather than evidence. The honest strategic point is that insights are now produced by a supply chain of sources, transformations, models, vendors, and reviewers. If we do not manage that supply chain, we will not know which insights deserve action, which require caution, and which should quietly be discarded.
Why provenance is strategic infrastructure, not paperwork
The commercial bottleneck in AI is no longer generation. It is confidence at the point of action. The McKinsey data carries a quiet implication: near-ubiquitous use, uneven value capture, and high performers who are more disciplined about when outputs need human validation. That does not prove validation alone creates value, but it strongly suggests that high-value AI is operationally disciplined AI. Put more plainly, the winners are not simply the fastest generators of output. They are the fastest producers of defensible output.
The trust data points the same way. When 66% of employees rely on outputs without checking them, and only around 40% say their workplace has any policy on generative AI, what you have is a classic leadership problem. People are operationalising AI faster than institutions are operationalising oversight. The cost of that is not only a higher error rate. It is the slow loss of institutional memory about how decisions were actually formed. This is why I argue provenance should be treated as infrastructure. It improves at least four value levers at once:
Decision latency. It reduces the time required to verify a claim before you can act responsibly.
Risk posture. It makes it far easier to identify which step introduced error, bias, privacy exposure, or unsupported inference.
Learning velocity. Teams can compare which prompts, models, retrieval sources, and review patterns produced reliable results, and repeat what worked.
Transferability. When people leave, the organisation keeps the method, not just the conclusion.
Those are strategic capabilities rather than compliance side-effects, and they sit comfortably alongside the OECD position that AI actors should ensure traceability across datasets, processes, and decisions, as well as NIST's framing of trustworthy AI as a lifecycle discipline rather than a single control. No board accepts a number simply because it looks plausible. They expect ledgers, controls, approvals, reconciliations, and auditability.
In the AI era, the equivalent discipline is to stop accepting a recommendation merely because it is articulate, and to start expecting an analytic ledger behind it. That single shift changes the organisation's default question from "Is this answer impressive?" to "Can we reconstruct and defend how this answer came to exist?" The second question is the one that makes an insight genuinely valuable.
What untraceable insights quietly break
The most obvious risk of a missing chain of custody is that you cannot tell whether a claim is grounded, guessed, or fabricated. The enterprise consequences extend beyond simple inaccuracy, now including legal liability, regulatory breaches, privacy exposure, operational drag, and reputational damage. Stanford HAI reports that documented AI incidents rose to 362 in 2025, up from 233 in 2024, while McKinsey finds that 51% of respondents at organisations using AI have already seen at least one negative consequence and nearly a third report consequences stemming from inaccuracy. These are no longer hypothetical edge cases. They are recurring operating events.
Three recent cases show the pattern with uncomfortable clarity. The common thread in each was not simply that an AI system hallucinated. It was that humans could not, or did not, preserve a credible source trail and validation process before acting on the output.
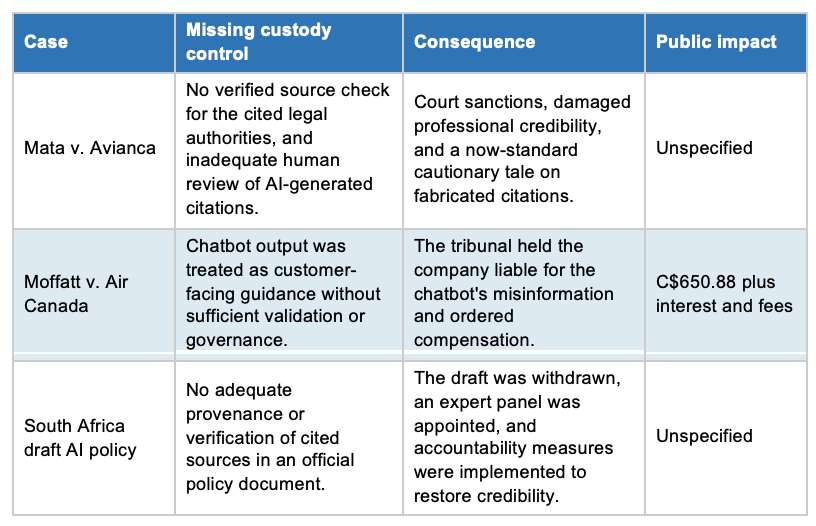
Privacy law makes the exposure even more concrete. The OAIC states that privacy obligations apply to both personal information entered into AI systems and AI-generated outputs that contain personal information. It warns that inferred, incorrect, or artificially generated information about identifiable individuals still counts as personal information and must be handled in accordance with the Australian Privacy Principles. It recommends, as a best practice, that organisations do not enter personal or especially sensitive information into publicly available generative AI tools, and that processes be designed around the real possibility that AI outputs may be wrong. If you cannot reconstruct what personal data was input, how it was transformed, and how accuracy was assessed, you will struggle to demonstrate compliance when it is asked of you.
Building chain of custody into culture, not just tooling
Technology is necessary here, but it is nowhere near sufficient. The hardest change is cultural. Organisations have to stop treating AI use as private craft and start treating it as institutional knowledge work. The Melbourne and KPMG findings make the stakes clear: hidden use is common, training is incomplete, and many people rely on outputs without checking them. The essential shift is to make disclosure and validation normal rather than exceptional, and again the publishing world gives us a clean template: disclose the tool, the model or version, what it was used for, how it was used, and who remains accountable for the final content.
The values that should anchor the operating model are not abstractions. They are operational criteria you can actually hold people to:
Accountability. Every material AI-assisted insight has a named owner who accepts responsibility for the final recommendation.
Transparency. The insight manifest is available to reviewers in proportion to the risk involved.
Epistemic humility. Outputs are labelled as verified facts, supported inferences, or speculative suggestions, rather than blended into one confident narrative.
Privacy and stewardship. Sensitive data is minimised, controlled, and never casually exposed to public models.
Contestability. Anyone affected by an insight or decision can challenge it and obtain the grounds on which it was formed.
From there, the most useful design move is to redesign workflows around validation thresholds rather than applying one rule to everything. Low-risk assistance, such as copy-editing or formatting, can sit under light-touch disclosure. Medium-risk work, such as research synthesis or internal analysis, should require citation checks, source manifests, and human sign-off. High-risk or externally consequential work, including pricing, credit, HR, legal and regulatory submissions, public policy, safety decisions, and customer entitlements, should require independent validation, preserved logs, retained prompts or prompt classes, model and version disclosure, and explicit approval gates. This mirrors the risk-based logic of the EU AI Act and the Australian public-sector practice of use-case registers, impact assessments, accountable officials, and training.
The sequence I recommend follows the strongest common elements across NIST, Australian public-sector guidance, OAIC privacy expectations, and the observed failure cases. Start with the material use cases, define what must be captured, instrument the stack, create validation gates, then scale and audit. The table below sets out that programme with indicative owners, timelines, and an effort-to-impact read.
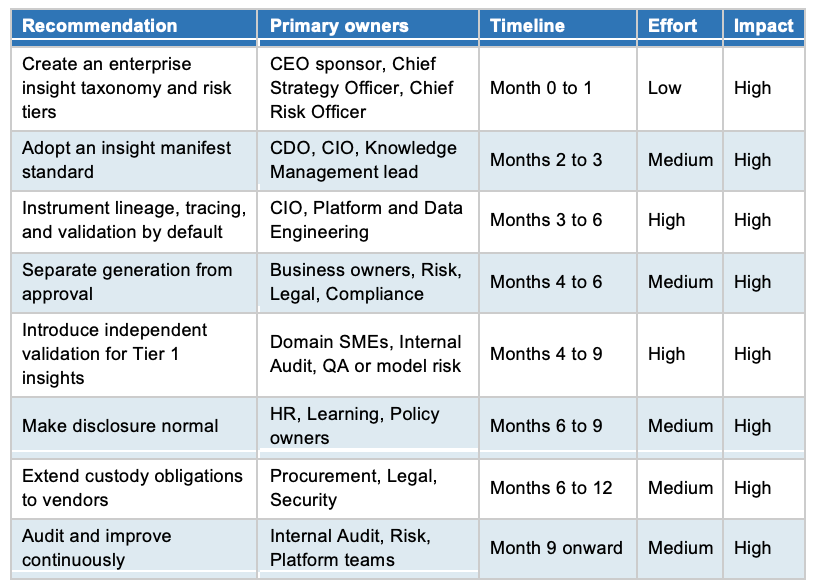
If that programme feels like a lot to begin, start smaller and start today. For most organisations, the fastest practical step is to attach a one-page manifest to each material insight. A robust minimum captures:
A unique insight ID, the creator, and the accountable owner.
Sources with persistent references, and the retrieval date.
The transformation steps and the AI systems used, including the model and version.
The prompt or prompt class, and any material human edits.
The validation methods used, and the validators who applied them.
The approval date, the risk tier, the retention location, and the downstream decisions influenced.
One rule makes the whole thing work. Where a field is not captured, the default entry should be the word unknown, never silence. Silence is precisely what destroys custody, because it hides the absence of a check behind the appearance of completeness. This minimum is strongly aligned with publishing disclosure norms, regulator expectations on transparency and oversight, and the assurance practices now expected in government.
A fair word on what is still moving
I want to be honest about the parts of this that are evolving quickly. Regulatory dates and guidance under the EU AI Act are current as of this writing and may continue to shift through implementing acts, codes of practice, and simplification processes. Tooling also changes fast, and official documentation can describe a capability while real-world completeness still depends on integration quality, vendor interoperability, and local process discipline. None of this weakens the central argument. If anything, it strengthens it. When the ecosystem is this fluid, traceable custody becomes more important, not less.
The judgement that now matters
The strategic question is no longer whether AI can generate insights quickly. It plainly can. The question worth asking in every leadership team is whether your organisation can defend, reproduce, and responsibly act on those insights when they are put under scrutiny. The W3C's provenance model, NIST's evidentiary logic, the OECD's traceability principle, the EU AI Act's logging obligations, Australia's accountability and transparency requirements, and the lived experience of courts, regulators, and organisations all point to the same conclusion. The value of an insight now depends on its provenance, its transformation history, and its validation record.
So here is the reframe I would leave you with. Treat your insights the way a careful board treats its numbers, and a court treats its evidence. Build the ledger, name the owner, keep the trail, and make the absence of a check visible rather than invisible. The organisations that understand this first will not just be safer. They will be quicker to deploy AI where it matters because they will know with confidence which insights have earned the right to be trusted.
If your team is wrestling with where to start on this, I am always happy to compare notes. The first manifest is usually easier to write than people expect, and it tends to change the conversation immediately.
I am a research strategist who partners with businesses, technology organisations, and SaaS teams to turn research into clear strategic direction and measurable impact. I work hands-on across the full research lifecycle, spanning academic, consulting, industry, and policy research, with a strong focus on evidence-based decision-making.
My expertise brings together data-driven insights, UX and CX (Voice of Customer) research, strategic research planning, stakeholder engagement, and robust survey and measurement design. Using a mix of primary and secondary research methods, I help organisations move beyond surface-level insights to understand what truly drives customer behaviour, product adoption, and long-term value.
As a customer-centred, insights-led researcher, I focus on uncovering human behaviours, habits, motivations, and attitudes to help teams design products, services, and strategies grounded in real-world needs. I’m particularly drawn to emerging technologies and SaaS environments, where strong research can shape how people learn, work, and interact at scale.
Beyond UX and customer research, I bring deep experience in strategic research program design, vendor management, and cross-sector collaboration. I work closely with senior stakeholders and interdisciplinary teams to ensure research findings are translated into actionable strategy, product roadmaps, and policy-ready recommendations.
I actively contribute to the research and technology community through thought leadership, including writing on Medium and publishing a LinkedIn newsletter focused on research practice and emerging industry trends. I also partner with SaaS companies to evaluate user research platforms and capabilities, providing practical, real-world feedback that informs product innovation.
Forward-thinking and outcomes-focused, I bridge academic rigour, industry innovation, and strategic insight to help organisations build better products, make confident decisions, and deliver meaningful customer experiences.


