Why Your AI Persona is Lying to You: The Danger of Data Overload in Synthetic Populations
How more data can sabotage synthetic consumer accuracy and why AI research needs domain-aware design.

It started in December 2025, with an 86-year-old grandmother in Lima, Peru, while working with Datum International, my team and I built AI digital twins of real Peruvian families. A real mother, at the lowest socioeconomic level in Peru, told Datum’s interviewer she was terrified her children would leave home. She expressed deep fear, cultural resistance, and a heartbreaking pragmatism about aging alone. Her digital twin? It said her children leaving home would be "a challenge, but I would feel proud." A synthetic 86-year-old grandmother then suggested she would use smartphone apps to manage her budget, despite the fact that only a small minority of elderly Peruvians have internet access. Her real-world counterpart did not even want to own a mobile phone.
That moment crystallized the question that would drive three months of empirical research: can AI synthetic consumers actually replicate real people's feelings and predict how they behave — and if so, under what conditions?
What followed was an investigation across more than half a million LLM interactions, 11,000 synthetic interviews conducted in early 2026, six commercially available AI models, and three countries, culminating in a head-to-head test against two years of real grocery purchases from a US household panel. The findings reveal that the market research industry's "more is better" approach to AI prompting is fundamentally flawed. While synthetic populations offer unprecedented speed and scale, they are currently plagued by a phenomenon known as Layer Interference, where excessive data causes AI to prioritize "role-playing" over actual behavioral evidence.
Three combined quantitative studies investigated the effectiveness of synthetic consumer populations by comparing AI-generated respondents against real-world data across distinct stages. The findings reveal a Domain-Dependent Information Hierarchy, demonstrating that optimal data representation for synthetic populations changes based on whether a task involves personality, deliberation, or habitual behavior. Specifically, while quantified personality scores excel at identity expression, they can actually contaminate behavioral predictions by causing the AI to prioritize "role-playing" over historical transaction evidence.
The studies show that AI frontier-tier models achieve modest accuracy in predicting grocery purchases, yet they struggle with a Brand Loyalty Wall due to a limited capacity for simulating loss aversion. Ultimately, the results suggest that research design and prompt architecture are significantly more important than the choice of AI provider. These findings advocate for a domain-aware cognitive router rather than a one-size-fits-all approach to synthetic market research.
What is the Domain-Dependent Information Hierarchy?
The Domain-Dependent Information Hierarchy is a framework for deciding which type of data an LLM should receive depending on the cognitive nature of the research task. The core idea is simple: the optimal type of data you should feed an AI depends entirely on the specific type of decision you want it to make.
Because human choices are driven by different cognitive processes, there is no universal, "one-size-fits-all" prompt. Instead, the framework maps out three distinct domains of decision-making, each requiring its own unique data representation:
1. The Identity Domain (Reflective)
What it is: This covers decisions related to self-concept, emotion, and identity expression, such as buying luxury goods, booking travel, or evaluating brand positioning.
What the AI needs: To simulate this accurately, the AI needs personality traits such as Openness, Conscientiousness, Extraversion, Agreeableness and Neuroticism, combined with a narrative description.
2. The Decision Domain (Deliberative)
What it is: This involves slow, careful choices that require weighing trade-offs, like buying durable goods (e.g., a washing machine) or evaluating financial products.
What the AI needs: Personality traits are not enough here. The AI instead requires a Decision Profile, which consists of specific parameters that dictate how a person reasons, such as their level of "loss aversion" or "temporal discounting".
3. The Operational Domain (Habitual)
What it is: This domain covers fast, routine, automatic behaviors, like buying weekly groceries or fast-moving consumer goods (FMCG).
What the AI needs: The AI performs best when given exclusively raw behavioral data (like past purchase frequencies, brand loyalty indexes, or average basket sizes).
The Golden Rule: Mixing Layers Hurts. One of the most important discoveries within this hierarchy is a phenomenon called Layer Interference. You might logically think that giving the AI all the information — personality, decision profiles, and behavioral data—would produce the most accurate simulation. In reality, combining data layers that belong to competing cognitive systems actually degrades the AI's accuracy.
For example, if you add personality data to raw behavioral data when trying to predict routine grocery purchases, the AI's accuracy drops by anywhere from 17% to 160%. This happens because the AI treats the personality data like a "character sheet" and starts role-playing, effectively ignoring the hard evidence of the consumer's actual purchase history.
Ultimately, the Domain-Dependent Information Hierarchy teaches us that to build a successful AI simulation platform, you cannot use one massive prompt. Instead, you need a domain-aware cognitive router—a system that first identifies whether a scenario requires identity, deliberation, or habit, and then feeds the AI only the specific layer of data optimized for that exact domain
How do different Data Layers interfere with Model Accuracy?
Different data layers interfere with model accuracy through a phenomenon the research identifies as "layer interference" or "semantic layer interference". This occurs when multiple data representations that engage competing cognitive systems are combined in a single prompt, causing the language model to integrate conflicting signals and degrade prediction accuracy.
The primary ways this interference manifests include:
The "Character Sheet" Override: When abstract personality data (such as OCEAN scores) is combined with raw behavioral data, the LLM treats the personality profile as a "character sheet" to role-play. This character construction overrides the actual empirical behavioral evidence because personality narratives are highly expressible in the LLM's native modality of text generation.
Semantic Register Conflicts: The LLM processes information differently depending on the "register" in which it is presented. Personality scores trigger a narrative register (prompting theatrical character role-playing), while behavioral or decision data triggers an operational register (acting as numerical constraints). When both are present, the narrative module tends to overpower the operational constraints, heavily contaminating the behavioral signal.
Domain Mismatch: Data layers that are highly effective for one cognitive domain actively mislead the model in others. For instance, while explicit "Decision Profiles" perfectly anchor deliberative decisions (System 2), injecting them into tasks about habitual grocery purchases (System 1) actually causes the model to anti-correlate with real-world behavior.
Concrete Evidence of Interference:
Addition by Subtraction: Across all tested models, removing OCEAN personality layers and relying only on raw behavioral data improved behavioral prediction accuracy by 17% to 160%, depending on the AI model.
Curation Failure: Even when researchers specifically curated the behavioral data down to the most critical attributes, the mere presence of OCEAN personality data alongside it still destroyed the model's predictive accuracy.
Disproportionate Impact on Smaller Models: Smaller, "budget-tier" models (like Claude Haiku and GPT 4o-mini) are disproportionately vulnerable to layer interference. Because they possess fewer parameters to balance competing information streams, the personality narrative completely overwhelms their limited capacity to follow behavioral evidence.
This demonstrates that for synthetic simulation, providing an LLM with "more context" can be often counterproductive. The prompt architecture—specifically activating the single optimal data layer for a given task while excluding interfering layers—is a far more critical determinant of accuracy than the choice of the language model itself.
Te Identity-Operation Gradient
Another key finding of this research is that LLMs are significantly better at simulating behaviors that function as identity markers rather than operational metrics.
Success (Identity-Explicit): Categories like "price sensitivity" or "bulk buying" act as self-concepts that the LLM can easily narrativize, leading to higher fidelity (mean r = 0.31).
Failure (Operational): Purely transactional data, such as "shopping frequency" or "basket size," provides no narrative anchor for the LLM. No consumer identifies as "a person who shops 2.3 times per week," so the LLM defaults to generic, often incorrect, patterns (mean r = 0.12).

The results redefine the limits of synthetic populations by exposing systematic biases:
The Wall: No model could faithfully simulate extreme brand loyalty (100% loyalty). When faced with price increases, LLMs defaulted to "Rational Agent" logic—switching brands for savings—even when the data indicated the household was strictly loyal.
Sycophancy: Models often default to "Virtue Projection" (e.g., choosing healthy options) or "Rationality" (e.g., always choosing the cheapest option) rather than projecting the actual assigned persona.
The Domain-Aware Cognitive Router
Research should move away from generic "persona" prompts. A production-ready synthetic population platform requires a domain-aware cognitive router that activates different data layers (personality vs. decision parameters vs. raw behavior) based on whether the specific research question is about identity, deliberation, or habit.
To illustrate this, in the stage 2 study, the research shifted from Personality Traits to Decision Profiles, revealing a sophisticated hierarchy of parameters that can be simulated with high fidelity, while others remain fundamentally out of reach for current LLMs. Each profile consists of specific numerical parameters that are mathematically derived from a person's OCEAN personality scores using published regression coefficients. These parameters, drawn from behavioral economics and cognitive psychology, include:
Loss aversion (λ): The tendency to prefer avoiding losses over acquiring equivalent gains.
Temporal discount (δ): How much a person devalues a reward based on its delay.
Exploration bonus (β): The tradeoff between exploring new options versus exploiting known ones.
Fairness threshold: Sensitivity to fairness in social dilemmas.
Model-based weight (ω): The reliance on model-based versus model-free decision strategies.
Confirmation bias: The tendency to interpret new evidence as confirmation of one's existing beliefs.
Why does it work? Even though Decision Profiles are derived from the exact same psychological traits as personality data, they succeed in anchoring decisions where raw personality scores fail. This is due to the semantic register in which the data is presented. When an LLM reads a personality trait like "Agreeableness = 80," it reads it in a narrative register, prompting it to theatrically act out the character of a "kind person," which often overrides behavioral evidence. However, when it reads a parameter like "Fairness threshold = 0.72," it reads it in an operational register, treating the number as a concrete constraint on a specific decision without the theatrical baggage.
However, LLMs do not handle all parameters equally well. Research shows model accuracy follows an identity-operation gradient:
High Accuracy (Identity-adjacent): Parameters that easily translate into a personal narrative, like moral sensitivity and cooperation tendency, are simulated with high fidelity.
Low Accuracy (Operational): Parameters that represent pure calculations or constraints, like risk calibration and loss aversion, perform much worse.
The study tested specific parameters across multiple models to determine which can be reliably "anchored" by numerical instructions.
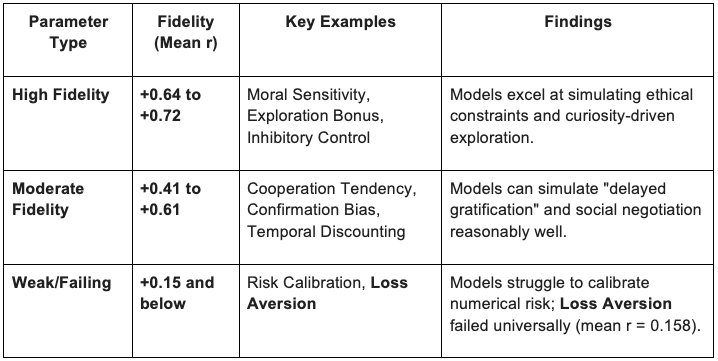
The researchers identified specific points where the simulation of human decision-making collapses:
The Loss Aversion Failure: This was the only parameter that failed across every model tested. This failure directly explains the "Brand Loyalty Wall" observed in Stage 3: because models cannot simulate high loss aversion (the pain of losing a familiar brand), they default to "Rational Agent" logic and switch brands for minor savings, even when real-world data shows strict loyalty.
The Resource Constraint Specialty: Interestingly, the budget-tier model Claude Haiku outperformed larger models (including Sonnet) in simulating Inhibitory Control and Cognitive Effort Cost. Researchers suggest that smaller models may be better at simulating "resource limitation" because they have fewer parameters to override prompt instructions with general "world knowledge."
The Sycophancy Sub-Shoot: In operational scenarios (like a store layout change), models often defaulted to a positive, adaptive "socially desirable" response rather than reflecting the frustration indicated by the behavioral data.
Why is loss aversion the hardest parameter to simulate?
Loss aversion is the most difficult parameter for Large Language Models (LLMs) to simulate—averaging a negligible correlation of r = 0.158 across all tested models—due to fundamental biases and cognitive processing limitations within the models themselves. The primary reasons loss aversion fails include:
The "Rational Agent" Bias: LLMs exhibit a systematic bias toward "loss-neutral economic rationality". They default to an economically rational state where they consistently choose the cheaper option, switch for savings, and utilize coupons. Because they act as hyper-rational agents, they fail to replicate the fundamentally "irrational" human tendency to avoid losses or stick with familiar products when a cheaper, viable alternative is available.
A Base Disposition of Openness: Due to their alignment training, LLMs default to engagement, enthusiasm, and openness. However, simulating high loss aversion often requires demonstrating resistance to external stimuli, such as ignoring a layout change, declining a free sample, or rejecting a new promotion. Simulating this resistance directly conflicts with the models' agreeable, exploratory base disposition.
Operational vs. Narrative Disconnect: Loss aversion sits at the bottom of the "identity-operation gradient". Unlike parameters such as moral sensitivity, which an LLM can easily narrativize to construct a "character," loss aversion is a purely operational constraint and calculation. LLMs struggle to anchor their behavior to pure calculations because there is no identity-based narrative for the model to grip.
The Loss Aversion Paradox (Decoupled Systems): The research reveals that an LLM's verbal expression is decoupled from its behavioral decision-making. For example, a model might correctly verbalize its assigned parameter by saying, "As someone with low loss aversion...", but it will then proceed to make a choice that demonstrates maximum loss aversion. The LLM can explicitly state the label without actually applying the mathematical constraint to its decision.
This abstract failure to simulate loss aversion has a very concrete consequence: because models cannot simulate the aversion to losing a familiar product, they are fundamentally unable to simulate consumers who are 100% loyal to a specific brand. Even when the prompt explicitly states that a persona is highly loyal, the model will readily abandon the familiar brand just to save a few dollars, completely overriding the behavioral parameter.
The Future of Market Research is a Hybrid Integration
These findings impose a clear responsibility on researchers: Synthetic populations must be treated as a filter, not an oracle. While they are highly effective for "Phase 0" exploration—narrowing 100 concepts down to 10—they cannot replace human respondents for "ground-truth" behaviors like unwavering brand loyalty or extreme price sensitivity.
If you are looking to integrate synthetic personas into your market research, here are the core implications you must follow:
Match the Task to the Right Cognitive Domain: You must recognize that synthetic personas have a distinct validity profile. They are highly effective for identity-expressive tasks (like concept testing, brand positioning, and message resonance) and deliberative evaluation (like trade-off analysis for durable goods). However, they consistently fail at predicting exact operational behaviors, such as habitual grocery purchase volumes, exact conversion rates, or unwavering brand loyalty.
Invest in Prompt Architecture, Not Just Bigger Models: The research shows a staggering variance decomposition: how a scenario is designed and framed explains approximately 76% of the simulation's accuracy, while the choice of AI model explains less than 4%. Rather than constantly paying for the most expensive frontier LLM, researchers should invest their engineering effort into crafting the right data layers and minimizing the "layer interference" we discussed earlier.
Use Identity Anchors for Better Simulation: As we touched on regarding the "semantic register," how you present data matters. A scenario designed to activate an identity narrative (e.g., framing a shopper as "highly price-sensitive" or "the kind of person who tries new things") will yield dramatically more accurate responses than simply feeding the AI operational metrics like "visits the store 2.3 times a week". The quality of your synthetic research output is heavily dependent on maximizing the identity valence of your behavioral prompts.
Prepare for a Methodological Migration: The shift to synthetic research is mirroring historical industry shifts, such as moving from face-to-face interviews to telephone, and later from telephone to online panels. Just as online surveys didn't completely kill telephone interviews but rather found their specific niche, synthetic research will not obsolete human research. It is simply a new methodology with its own strengths (rapid exploration of massive parameter spaces) and weaknesses (inability to simulate certain habitual constraints).
Instead of full replacement, researchers should view synthetic personas as an augmentation tool. The data points toward a hybrid workflow: you can use synthetic populations to test 100 early-stage concepts, use the results to narrow them down to 10 survivors, and then validate those final 10 with real consumers before launching the top 3.
The future of market research lies in the calibration of AI and humans. By using a domain-aware approach, we can leverage AI for what it does best—rapid exploration of the identity and deliberative domains—while relying on human panels to anchor the operational behaviors that AI is currently "too rational" to understand.
Adriana Rocha
Founder at Wortya, Founder at Wisdom Beyond TechnologyAdriana Rocha is an AI researcher, engineer, entrepreneur, and author of Refactoring the Firm: Building Intelligence-Native Organizations for the AI Age. She is the founder of Wisdom Beyond Technology and Wortya. The qualitative study in Peru was conducted in collaboration with Datum International.


